In this post I review how to build a compartmental model using the Stan probabilistic computing language. This is based largely by the case study, Bayesian workflow for disease transmission modeling in Stan which has been expanded to include a second compartment for exposed individuals as well as utilise case incidence data rather than prevalence.
- Online documentation and vignettes at mc-stan.org/cmdstanr
- CmdStan path set to: /Users/michael/.cmdstanr/cmdstan-2.28.2
- Use set_cmdstan_path() to change the path
A newer version of CmdStan is available. See ?install_cmdstan() to install it.
To disable this check set option or environment variable CMDSTANR_NO_VER_CHECK=TRUE.
Compartment models are commonly used in epidemiology to model epidemics. Compartmental model are composed of differential equations and captured some “knowns” regarding disease transmission. Because these models seek to simulate/ model the epidemic process directly, they are are somewhat more resistant to some biases (e.g. missing data). Strong-ish assumptions must be made regarding disease transmission and varying level of detail can be included in order to make the models closer to reality.
First we need to define our data generating process. Here we will start with a four compartment model with no births or deaths. This will represent an immunizing infection with a latent phase.
Warning in node_aes(fill = "orange"): partial argument match of 'fill' to
'fillcolor'
Warning in node_aes(fill = "orange"): partial argument match of 'fill' to
'fillcolor'
Warning in node_aes(fill = "orange"): partial argument match of 'fill' to
'fillcolor'
Warning in node_aes(fill = "orange"): partial argument match of 'fill' to
'fillcolor'
render_graph(a_graph, layout ="nicely")
Warning: The `x` argument of `as_tibble.matrix()` must have unique column names if `.name_repair` is omitted as of tibble 2.0.0.
Using compatibility `.name_repair`.
This warning is displayed once every 8 hours.
Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.
Simulate an Epidemic with Knowns
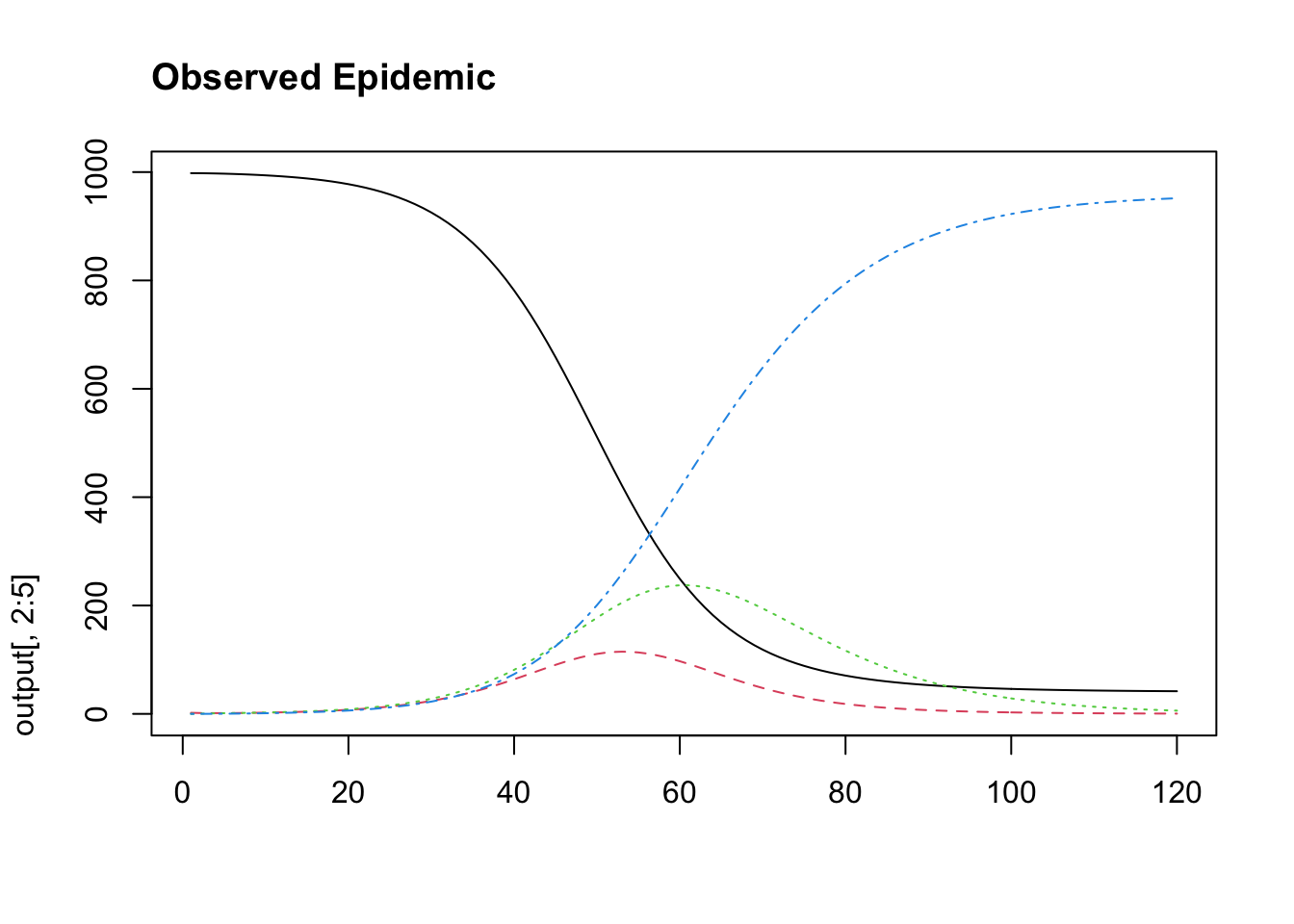
Now we can build this hypothetical epidemic using the “deSolve” package from R. Ideally, we will be able to recover our model parameters using our Bayesian model. This gives us confidence in fitting real data that we observe. This is a key step in the Bayesian workflow where we generate fake data, fit the fake data, and then examine the fit to ensure that we recover the real parameter before we fit our observed data.
seir_model =function (current_timepoint, state_values, parameters){# create state variables (local variables) S = state_values [1] # susceptibles E = state_values [2] # exposed I = state_values [3] # infectious R = state_values [4] # recovered N = state_values [1] + state_values [2] + state_values [3] +state_values [4]with ( as.list (parameters), # variable names within parameters can be used {# compute derivatives dS = (-beta * S * I)/N dE = (beta * S * I)/N - (delta * E) dI = (delta * E) - (gamma * I) dR = (gamma * I)# combine results results =c (dS, dE, dI, dR)list (results) } )}beta_value <-1/3gamma_value <-1/10delta_value <-1/4parameter_list <-c (beta = beta_value, gamma = gamma_value, delta = delta_value)times <-1:120initial_values <-c(S=1000-2, E =2, I =0, R =0)output =lsoda (initial_values, times, seir_model, parameter_list)matplot(output[,2:5], main ="Observed Epidemic", type ="l", adj =0)
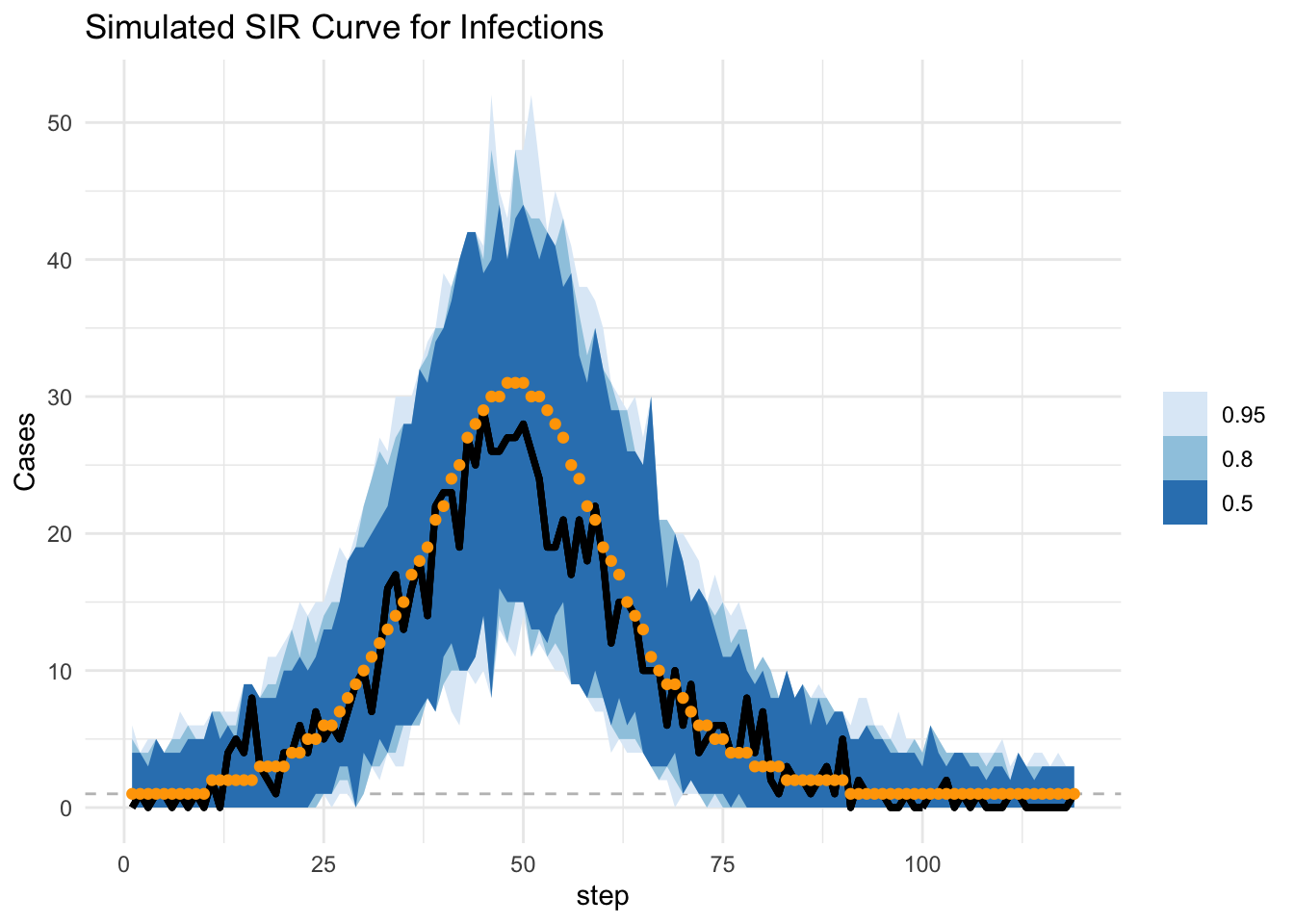
We can extract the daily incidence using the following equation. This represents what would typically be reported by authorities. To make it more realistic, it would be good to convolve the cases with a delay distribution to indicate the lag we observe in case reporting. A deconvolution step could then be written into Stan in order to account for this delay distribution.
Now let’s calculate our basic reproduction number or \(R_0\)
beta_value/gamma_value
[1] 3.333333
Build Model in Stan
Now we can build the model in Stan as shown below. Ideally, I would write the ODE solver using the new syntax, but I’ll leave that to next time. We can see that the differential equations have been built into the “sir” function.
mod <-cmdstan_model("sir.stan")mod$print()
Warning in readLines(self$stan_file()): incomplete final line found on
'/Users/michael/blog/quarto-blog/programming/2020-08-28-bayesian-sir/sir.stan'
// Based on https://mc-stan.org/users/documentation/case-studies/boarding_school_case_study.html
functions {
real[] sir(real t, real[] y, real[] theta,
real[] x_r, int[] x_i) {
real S = y[1];
real E = y[2];
real I = y[3];
real R = y[4];
real N = x_i[1];
real beta = theta[1];
real delta = theta[2];
real gamma = theta[3];
real dS_dt = -beta * I * S / N;
real dE_dt = beta * I * S / N - delta * E;
real dI_dt = delta*E - gamma * I;
real dR_dt = gamma * I;
return {dS_dt, dE_dt, dI_dt, dR_dt};
}
}
data {
int<lower=1> n_days;
real y0[4];
real t0;
real ts[n_days];
int N;
int cases[n_days-1];
int n_pred;
real ts_pred[n_pred];
real delta_mu;
}
transformed data {
real x_r[0];
int x_i[1] = { N };
}
parameters {
real<lower=0> theta[3];
real<lower=0> phi_inv;
}
transformed parameters{
real y[n_days, 3];
real<lower=0> phi = 1. / phi_inv;
real<lower=0> incidence[n_days-1];
{
y = integrate_ode_rk45(sir, y0, t0, ts, theta, x_r, x_i);
}
//for (i in 2:(n_days-1)) {
for (i in 1:(n_days-1))
incidence[i] = y[i, 1] - y[i + 1, 1];
}
model {
//priors
theta[1]~ normal(2, 1); //beta
theta[2]~ normal(delta_mu, .1); //delta
theta[3]~ normal(0.1, 0.7); //gamma
phi_inv ~ exponential(2);
cases ~ neg_binomial_2(incidence, phi);
}
generated quantities {
real R0 = theta[1] / theta[3];
real recovery_time = 1 / theta[3];
real pred_cases[n_days-1];
real pred_cases_out[n_pred-1];
real pred_incidence[n_pred-1];
// future prediction parameters
real y_pred[n_pred, 3];
real y_init_pred[3] = y[n_days, ]; // New initial conditions
real t0_pred = ts[n_days]; // New time zero is the last observed time
pred_cases = neg_binomial_2_rng(incidence, phi);
y_pred = integrate_ode_rk45(sir, y_init_pred, t0_pred, ts_pred, theta, x_r, x_i);
for (i in 1:(n_pred-1))
pred_incidence[i] = y_pred[i, 1] - y_pred[i + 1, 1];
pred_cases_out = neg_binomial_2_rng(pred_incidence, phi);
}
Build Dataset
Now we can prep our dataset for Stan.
# total countN <-1000;# timesn_days <-length(cases) +1t <-seq(0, n_days, by =1)t0 =0t <- t[-1]#initial conditionsi0 <-1e0 <-0s0 <- N - i0r0 <-0y0 =c(S = s0, E = e0, I = i0, R = r0)
Run the Model
Then we can run it using CmdStanR.
# number of MCMC stepsniter <-2000n_pred <-21data_sir<-list(n_days = n_days, y0 = y0,t0 = t0, ts = t, N = N, cases = cases,n_pred = n_pred,delta_mu=.2,ts_pred =seq(n_days+1, n_days+n_pred, by =1) )fit <- mod$sample(data = data_sir,adapt_delta = .9,chains =2, max_treedepth =12,parallel_chains =2,iter_sampling = niter/2,refresh =0,iter_warmup = niter/2)
Running MCMC with 2 parallel chains...
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: integrate_ode_rk45: ode parameters and data[3] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: integrate_ode_rk45: ode parameters and data[3] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: sir_model_namespace::log_prob: incidence[sym1__] is nan, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: integrate_ode_rk45: ode parameters and data[3] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: integrate_ode_rk45: ode parameters and data[3] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: sir_model_namespace::log_prob: incidence[sym1__] is nan, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: integrate_ode_rk45: Failed to integrate to next output time (1) in less than max_num_steps steps (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: integrate_ode_rk45: Failed to integrate to next output time (1) in less than max_num_steps steps (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: neg_binomial_2_lpmf: Location parameter[1] is 0, but must be positive finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 68, column 2 to column 41)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: integrate_ode_rk45: ode parameters and data[1] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: integrate_ode_rk45: Failed to integrate to next output time (1) in less than max_num_steps steps (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: sir_model_namespace::log_prob: incidence[sym1__] is -3.86535e-12, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: sir_model_namespace::log_prob: incidence[sym1__] is -2.92027e-09, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: sir_model_namespace::log_prob: incidence[sym1__] is -5.53462e-09, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: integrate_ode_rk45: ode parameters and data[3] is inf, but must be finite! (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 2 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 2 Exception: sir_model_namespace::log_prob: incidence[sym1__] is nan, but must be greater than or equal to 0.000000 (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 48, column 2 to column 36)
Chain 2 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 2 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 2
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: integrate_ode_rk45: Failed to integrate to next output time (1) in less than max_num_steps steps (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 52, column 4 to column 61)
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Chain 1
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 2 finished in 186.8 seconds.
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 Exception: no more storage available to write (in '/var/folders/0x/6bnjy4n15kz8nbfbbwbyk3pr0000gn/T/RtmpKDvWuP/model-1714d7187eea2.stan', line 90, column 3 to column 60)
Chain 1 finished in 207.0 seconds.
Both chains finished successfully.
Mean chain execution time: 196.9 seconds.
Total execution time: 220.9 seconds.
Warning in seq.default(from = 1, len = along - 1): partial argument match of
'len' to 'length.out'
Warning in seq.default(to = N - 1, len = N - along): partial argument match of
'len' to 'length.out'
Warning in seq.default(len = N): partial argument match of 'len' to 'length.out'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = length(arg.list)): partial argument match of 'len'
to 'length.out'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = ncol(arg.dim)): partial argument match of 'len' to
'length.out'
Warning in seq.default(len = N): partial argument match of 'len' to 'length.out'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = length(arg.names)): partial argument match of 'len'
to 'length.out'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(from = 1, len = along - 1): partial argument match of
'len' to 'length.out'
Warning in seq.default(to = N - 1, len = N - along): partial argument match of
'len' to 'length.out'
Warning in seq.default(len = N): partial argument match of 'len' to 'length.out'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = length(arg.list)): partial argument match of 'len'
to 'length.out'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = ncol(arg.dim)): partial argument match of 'len' to
'length.out'
Warning in seq.default(len = N): partial argument match of 'len' to 'length.out'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(along = arg.names): partial argument match of 'along' to
'along.with'
Warning in seq.default(len = length(arg.names)): partial argument match of 'len'
to 'length.out'
Warning in seq.default(along = perm): partial argument match of 'along' to
'along.with'
Finally, we can visualise our model outputs and see if we capture our actual cases. Additionally, I am using ggdist to capture the full range of possibilities as discussed in in my previous blog post
library(rstan)
Loading required package: StanHeaders
rstan version 2.26.3 (Stan version 2.26.1)
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
For within-chain threading using `reduce_sum()` or `map_rect()` Stan functions,
change `threads_per_chain` option:
rstan_options(threads_per_chain = 1)
Attaching package: 'rstan'
The following object is masked from 'package:magrittr':
extract
library(ggdist)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:data.table':
between, first, last
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
extract(fit_sir, pars ="pred_cases")[[1]] %>%as.data.frame() %>%mutate(.draw =1:n()) %>% tidyr::gather(key,value, -.draw) %>%mutate(step = readr::parse_number(stringr::str_extract(key,"\\d+"))) %>%group_by(step) %>%curve_interval(value, .width =c(.5, .8, .95)) %>%ggplot(aes(x = step, y = value)) +geom_hline(yintercept =1, color ="gray75", linetype ="dashed") +geom_lineribbon(aes(ymin = .lower, ymax = .upper)) +scale_fill_brewer() +labs(title ="Simulated SIR Curve for Infections",y ="Cases" )+geom_point(data =tibble(cases = cases, t =1:length(cases)),aes(t, cases), inherit.aes =FALSE, colour ="orange")+theme_minimal()
Looks like this model adequately captured our fake data! Part 2 will fit some real data.