This post explores using tools to summarise curves rather than fixed time summary methods. This includes using odin and ggdist to explore the risk of underestimating epidemic curves.
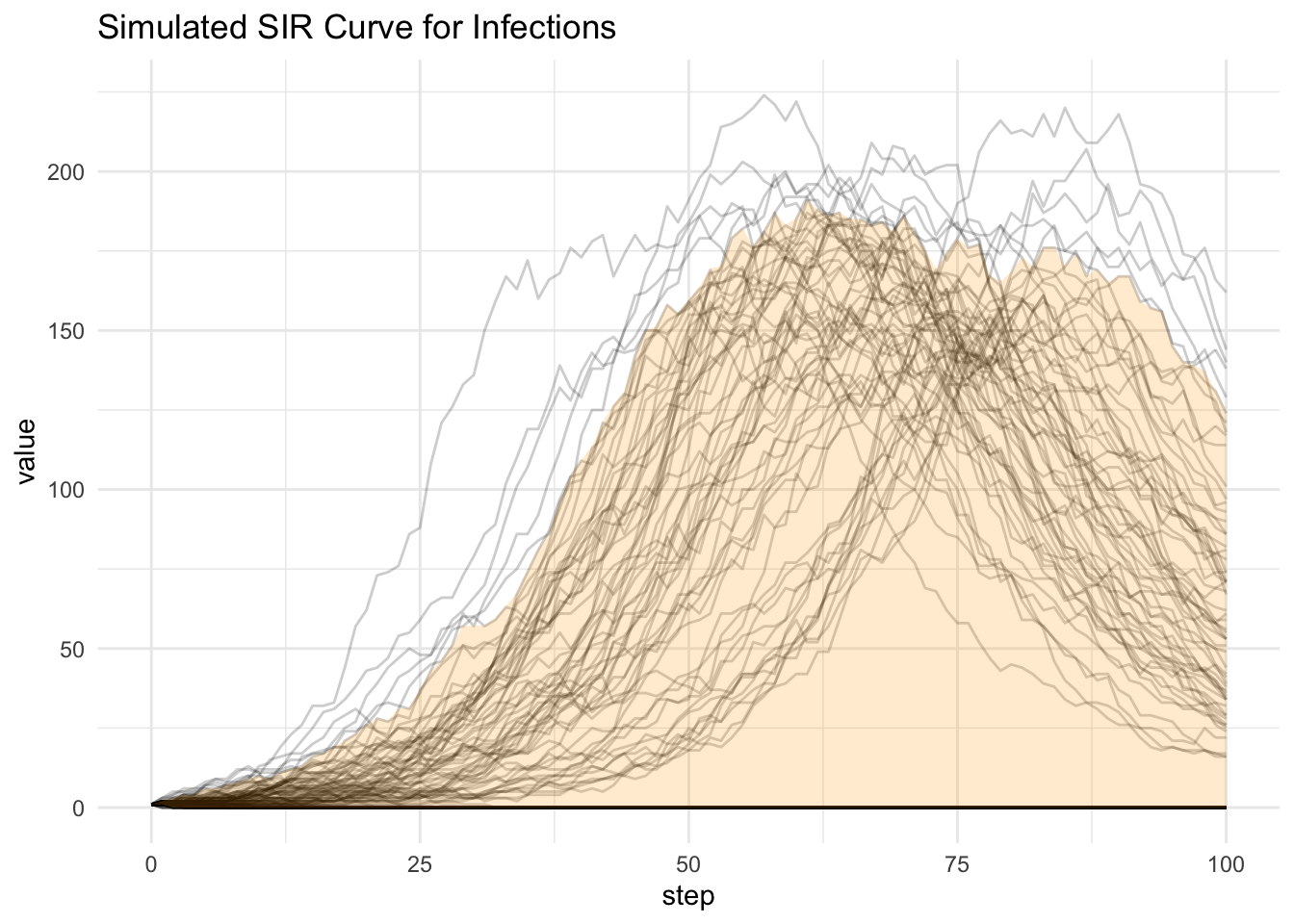
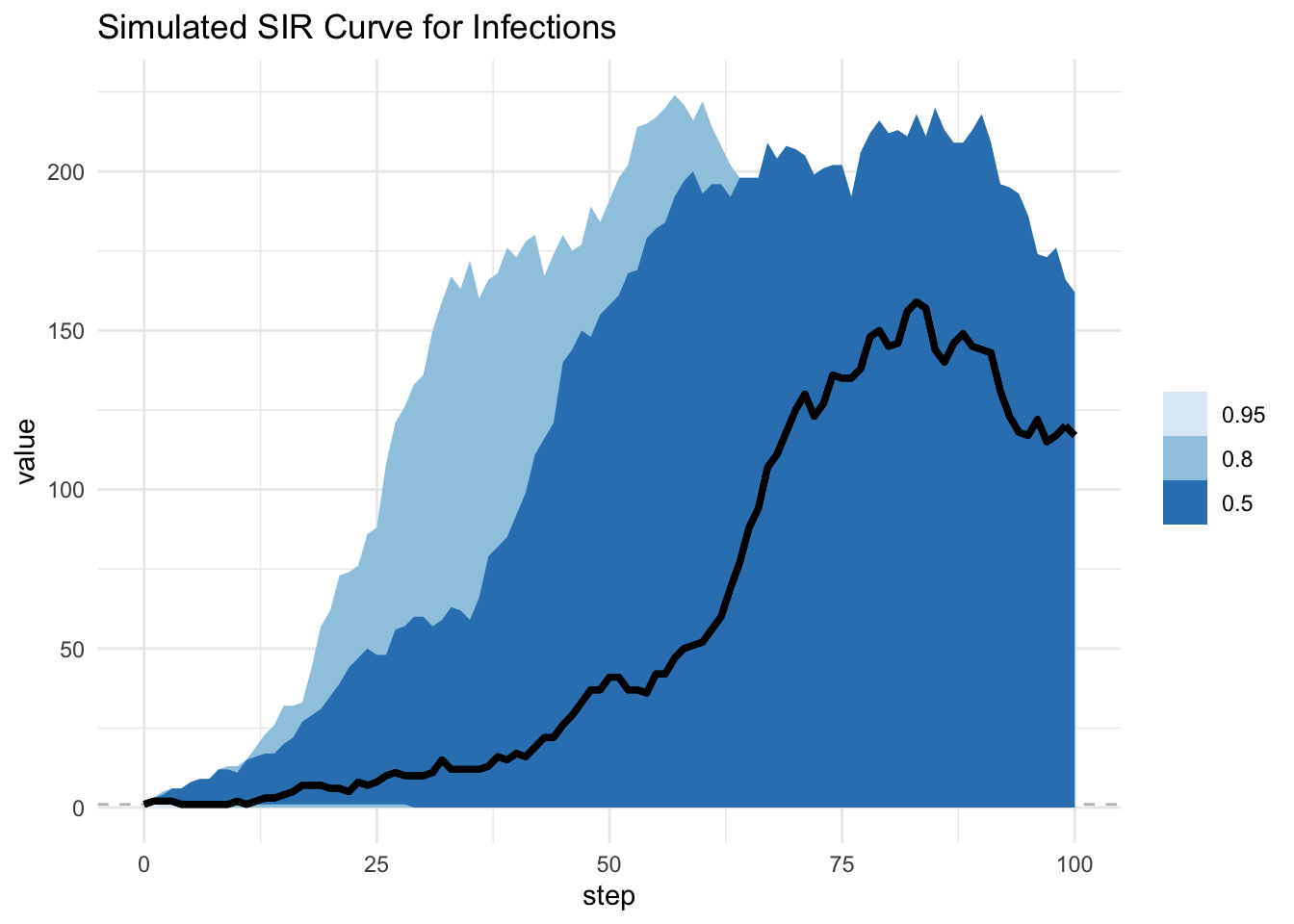
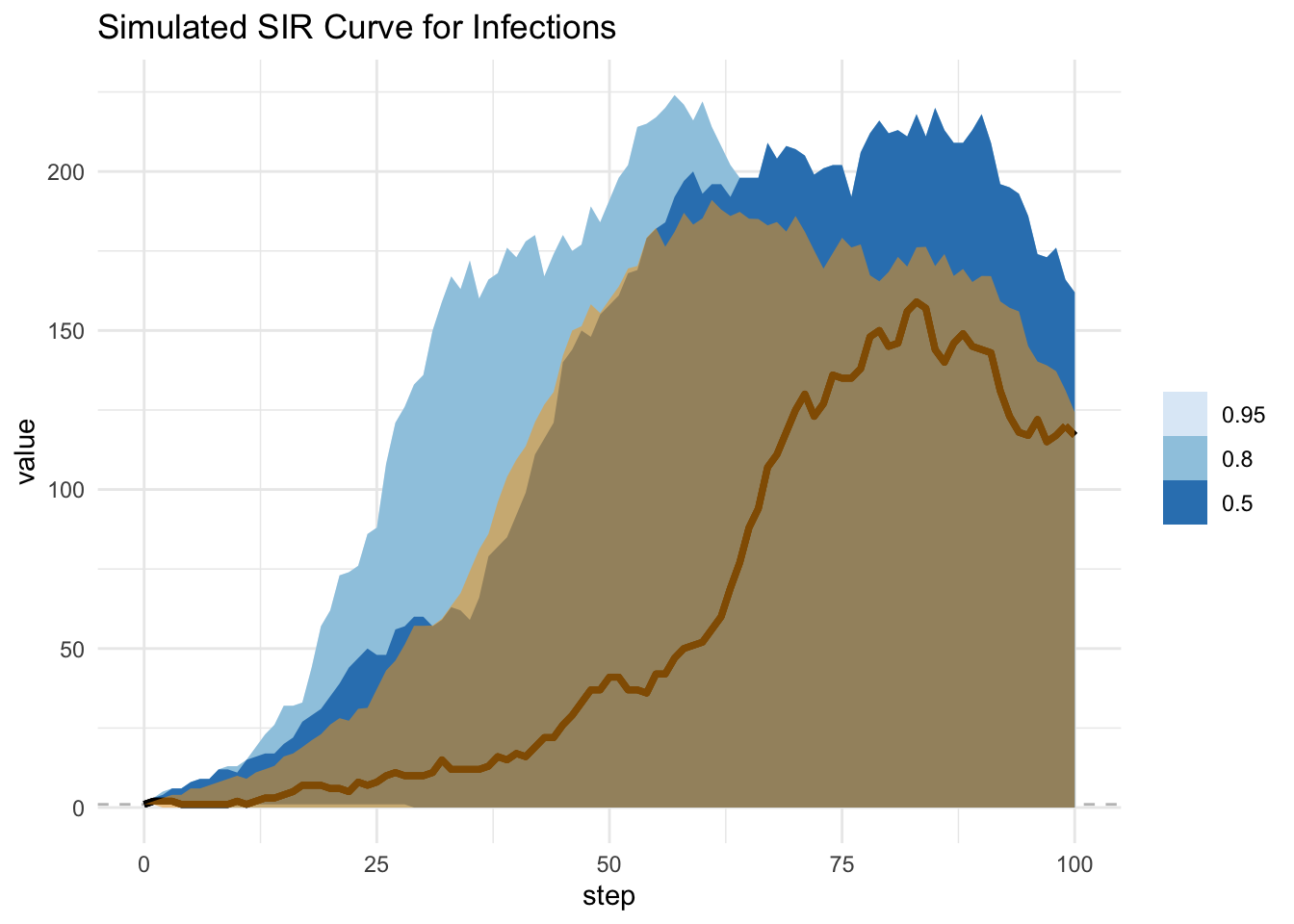
This little post is based on a recent paper by Juul et al. (2020). For infectious disease modelling we are often running many scenarios through the models. Why? Because there are many parameters to estimate, but very few things that we actually observe (cases by day or incidence) so in some sense our models all suffer from identifiability issues. Additionally, many of the parameters that we do measure have some uncertainty around them. For this reason it is very common to run models with different parameters estimates or distributions in order to understand a range of possible values. A simple way to summarise these models is through point-wise quantiles through time. The genius of Juul’s paper is that this can underestimate many outcomes because it might pick up the beginning of one epidemic curve and miss the peak.
Enter curve estimates. These measures actually look at the curves proper through the trajectory rather than at discrete time points. Here we can rank the entire curve and capture the contribution of the curve rather than the point-wise estimate.
To see this let’s run a simple example from the odin package (FitzJohn 2019). Additionally, the amazing ggdist (Kay 2020) provides an easy way to summarise curves.
We see that using the fixed time method we underestimate the peak much of the time! This is very dangerous and important when setting policy and establishing needs.