
library(DiagrammeR)
grViz("
digraph boxes_and_circles {
# a 'graph' statement
graph [overlap = true, fontsize = 10]
# several 'node' statements
node [shape = box,
fontname = Helvetica]
U; X; Y; Z;
node [shape = circle,
fixedsize = true,
width = 0.9] // sets as circles
U; X; Y; Z;
# several 'edge' statements
U->X X->Y Z->Y Z->X
}
")One important concept to discuss is that of omited variable bias. This occurs when you have endogenous predictors that you do not adequately control for in your analysis.
Fake Data Simulation
As with all analysis it is best to begin with a fake data simulation in order to build intuition about the problem. In this example suppose that we have some relationship that we would like to test where X predicts Y. Additionally, let’s suppose that there is some variable that affects by X and Y called Z.
Create the Fake Data
n <- 1000
U <- rnorm(n, 5, 1)
Z <- rnorm(n, 1, 1)
X <- rnorm( n, U + 1* Z, 1)
Y <- rnorm(n ,X + 1*Z, 1)Let’s inspect out data and see what kind of relationship we would expect:
plot(X, Y)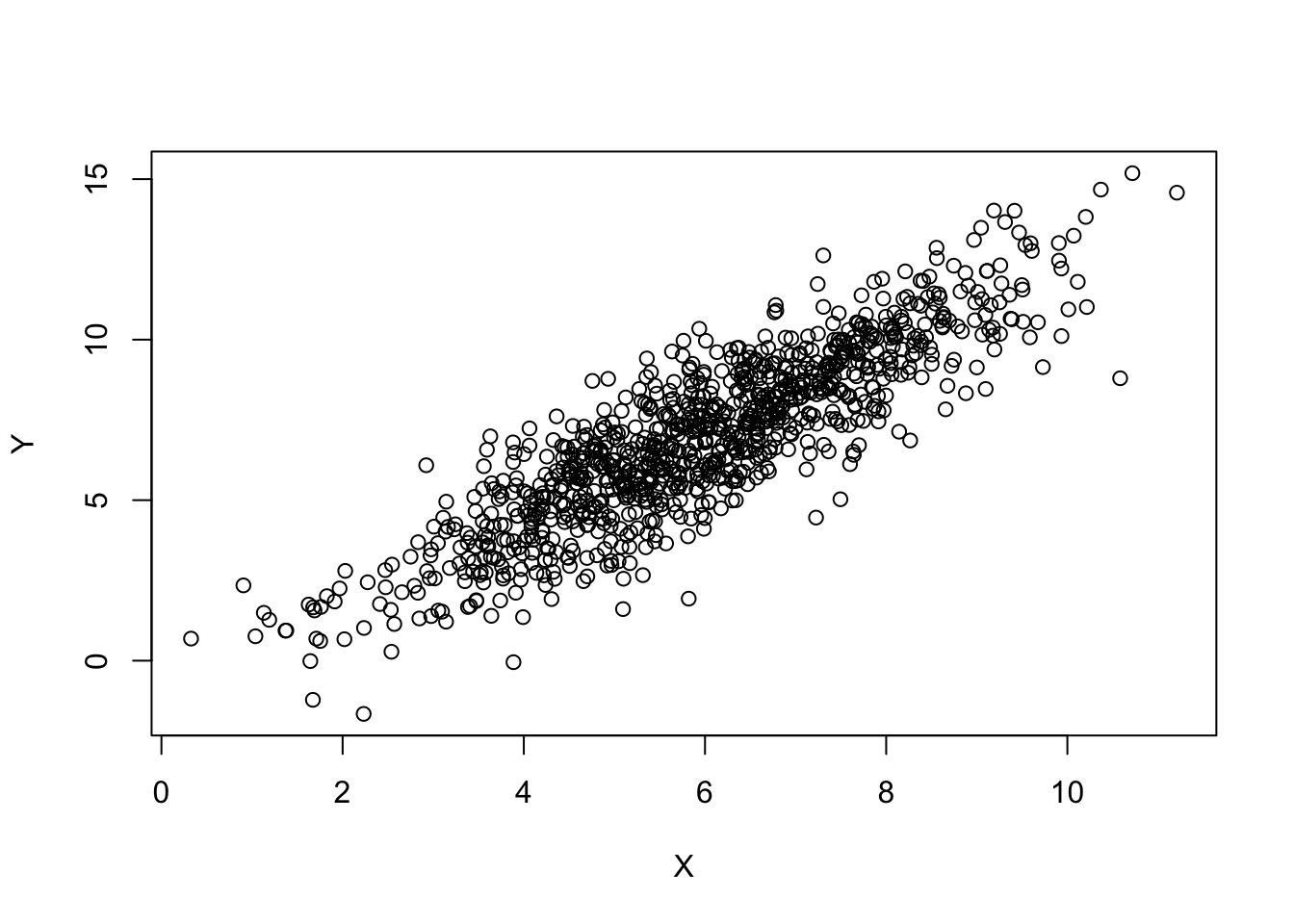
So if we were to do a naive linear regression of X on Y we would get the following results:
fit1 <- lm(Y ~ X)
arm::display(fit1)Warning in summ$coef: partial match of 'coef' to 'coefficients'
Warning in summ$coef: partial match of 'coef' to 'coefficients'
Warning in summ$coef: partial match of 'coef' to 'coefficients'lm(formula = Y ~ X)
coef.est coef.se
(Intercept) -1.01 0.15
X 1.33 0.02
---
n = 1000, k = 2
residual sd = 1.30, R-Squared = 0.76It’s a pretty good fit, but let’s look at when we include our omitted variable.
fit2 <- lm(Y ~ X + Z)
arm::display(fit2)Warning: partial match of 'coef' to 'coefficients'
Warning: partial match of 'coef' to 'coefficients'
Warning: partial match of 'coef' to 'coefficients'lm(formula = Y ~ X + Z)
coef.est coef.se
(Intercept) 0.03 0.12
X 0.99 0.02
Z 1.02 0.04
---
n = 1000, k = 3
residual sd = 1.00, R-Squared = 0.86So here we see that when we include our omitted variable our R2 increases and our coefficient estimates change slightly, though the biggest change is a shrinking of our standard errors.
All this to say that it is good to inspect for omitted variable and more importantly to do the fake data simulations to see how sensitive your model is to them.
Reuse
Citation
BibTeX citation:
@online{dewitt2019,
author = {Michael DeWitt},
title = {Omitted {Variable} {Bias}},
date = {2019-04-07},
url = {https://michaeldewittjr.com/programming/2019-04-07-omitted-variable-bias},
langid = {en}
}
For attribution, please cite this work as:
Michael DeWitt. 2019. “Omitted Variable Bias.” April 7,
2019. https://michaeldewittjr.com/programming/2019-04-07-omitted-variable-bias.