
library(ggplot2)
library(gghighlight)gghighlight is a package that is on cran that allows one to highlight certain features ones finds valuable. Right now I typically do this with some custom color coding, then pass that into the ggplot2 arguments. This might serve as a good way to more easily automate this task. Additionally, this could be super handy during exploratory analysis where this is much more iterative to find patterns.
Our libraries of course….
This code is copied directly from here.
Build some data which is more some white noise with a random walk.
set.seed(2)
d <- purrr::map_dfr(
letters,
~ data.frame(idx = 1:400,
value = cumsum(runif(400, -1, 1)),
type = .,
stringsAsFactors = FALSE))Definitely some messiness and colour overload!
ggplot(d) +
geom_line(aes(idx, value, colour = type))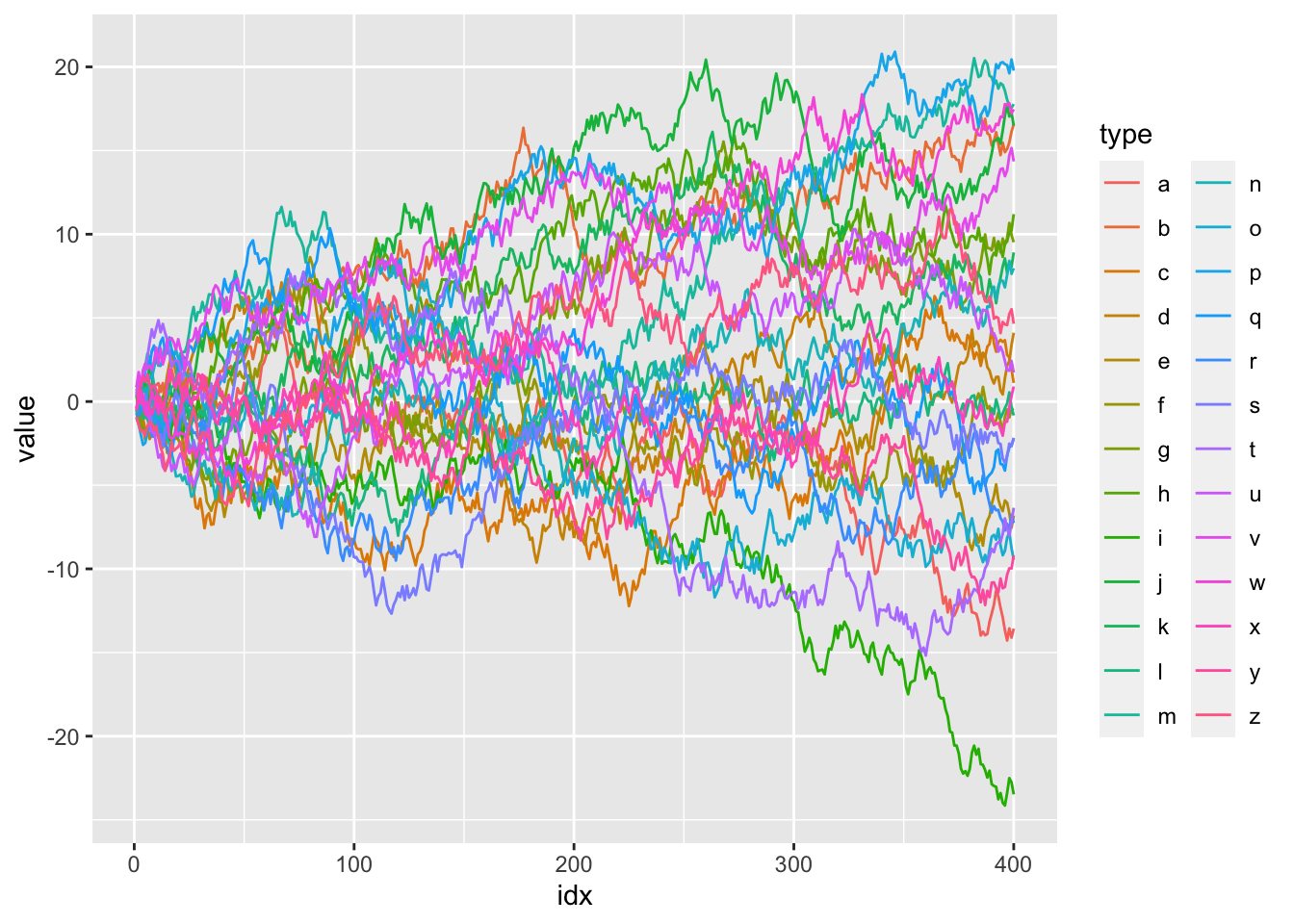
The way I would do it…
library(dplyr, warn.conflicts = FALSE)
d_filtered <- d %>%
group_by(type) %>%
filter(max(value) > 20) %>%
ungroup()
ggplot() +
# draw the original data series with grey
geom_line(aes(idx, value, group = type), data = d, colour = alpha("grey", 0.7)) +
# colourise only the filtered data
geom_line(aes(idx, value, colour = type), data = d_filtered)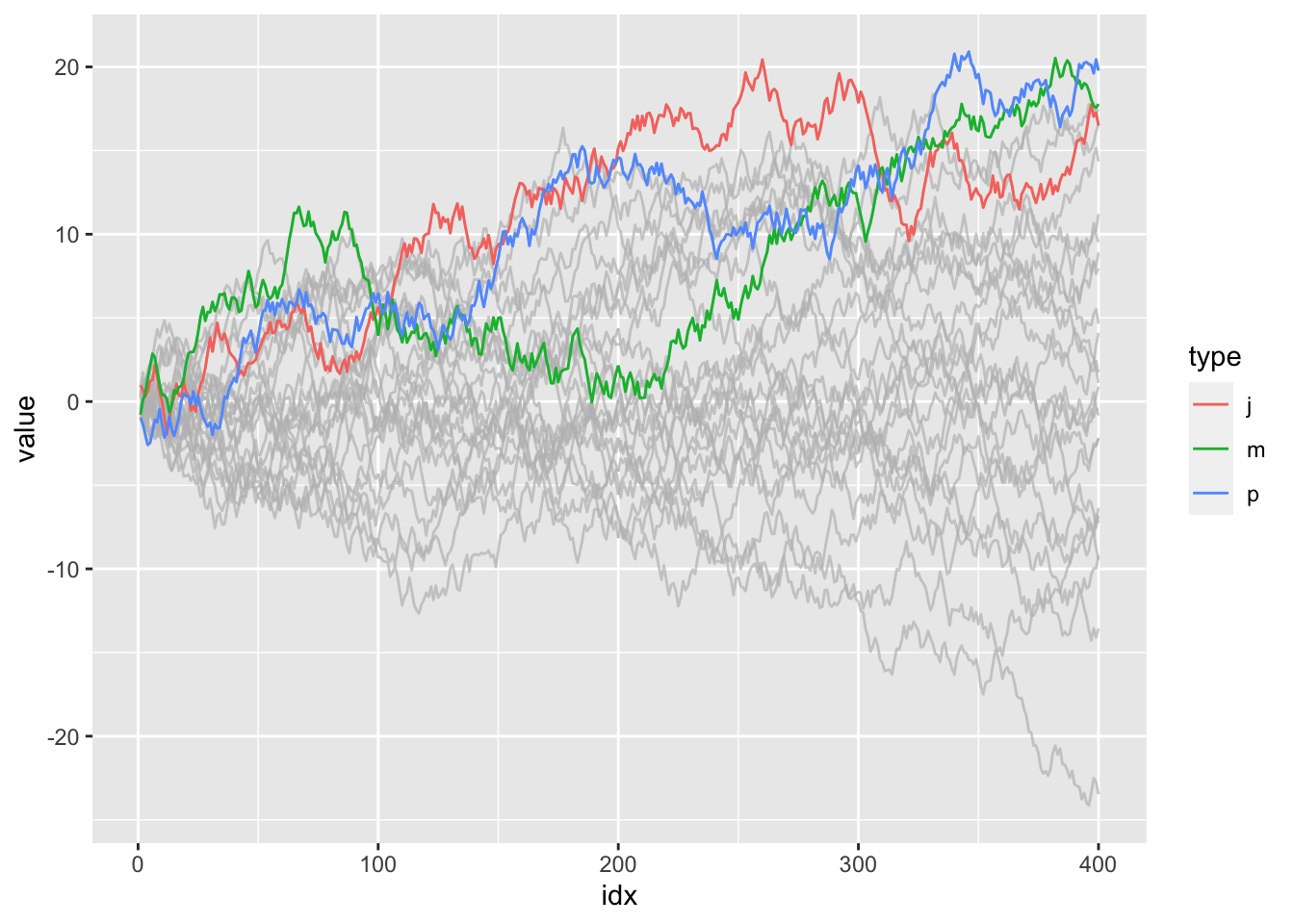
Now with this handy package we can do the following:
ggplot(d, aes(idx, value, colour = type))+
geom_line()+
gghighlight(max(value) > 20, label_key = type) +
theme_minimal()Warning: Using `across()` in `filter()` is deprecated, use `if_any()` or
`if_all()`.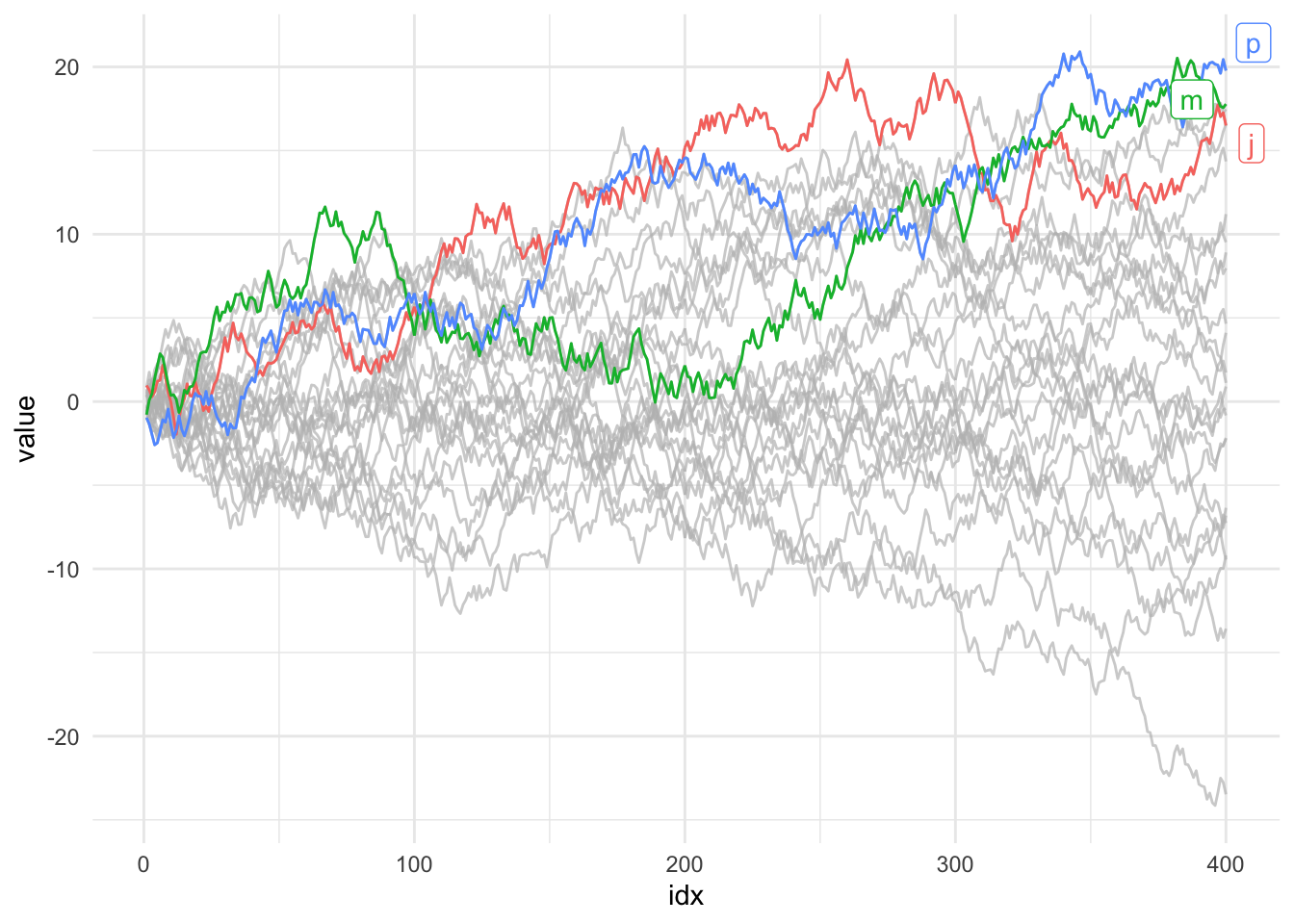
And because it is a ggplot object we can add things to it.
ggplot(d, aes(idx, value, colour = type))+
geom_line()+
gghighlight(max(value) > 20, label_key = type) +
theme_minimal()+
facet_wrap(~type)Warning: Using `across()` in `filter()` is deprecated, use `if_any()` or
`if_all()`.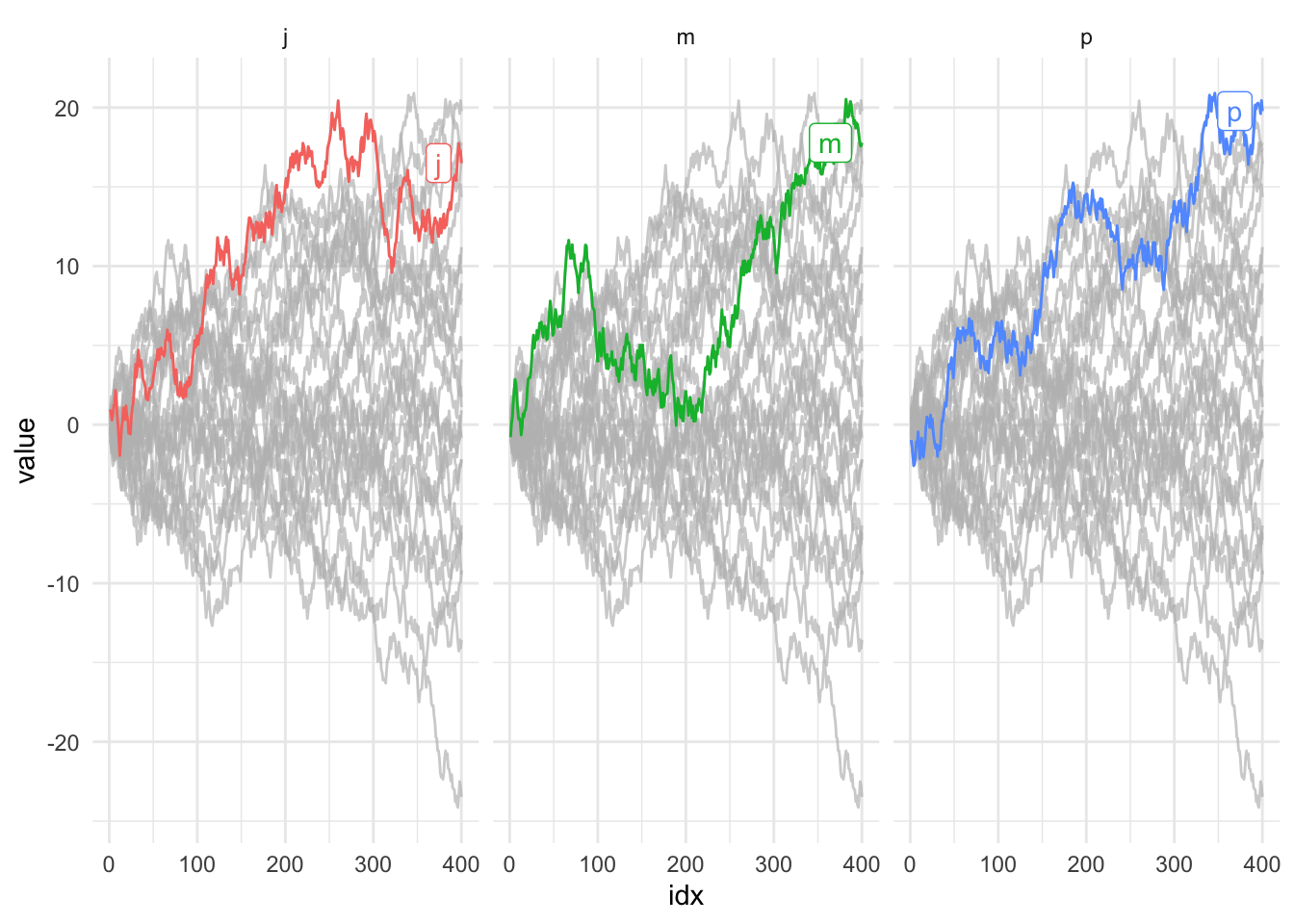
The package author does offer a caveat that the package can run slowly with lots of data and filtering and to go back to using dplyr in a discrete step. I imagine it is because of all the grouped operations? Dunno, but this is a neat package to use for exploratory work.
Reuse
Citation
BibTeX citation:
@online{dewitt2018,
author = {Michael DeWitt},
title = {Gghighlight for the Win},
date = {2018-07-04},
url = {https://michaeldewittjr.com/programming/2018-07-04-gghighlight-for-the-win},
langid = {en}
}
For attribution, please cite this work as:
Michael DeWitt. 2018. “Gghighlight for the Win.” July 4,
2018. https://michaeldewittjr.com/programming/2018-07-04-gghighlight-for-the-win.